一、ForkJoin 框架
1、简介
ForkJoinPool 是从 JDK 1.7 开始加入 Java 并发大家庭的,之前的继承图提到 ForkJoinPool 继承自 AbstractExecutorService,它具有线程池的所有特性,同时 ForkJoinPool 是为了运行 ForkJoinTask 任务而设计的。
ForkJoinPool 和其他线程池最大的不同就是该池中的线程采取了一种名为 work-stealing 的工作方式,直译过来就是 工作窃取:池中所有的线程会去尝试找到并执行已经提交到池中的任务(或者其他活动任务创建的子任务),最终执行完所有任务后,线程就会阻塞直到新任务到来。
这种奇特的工作方式也意味着 ForkJoinPool 要执行的任务不同于其他线程池,JUC 提供 ForkJoinTask 这一抽象类来描述这种任务。
public abstract class ForkJoinTask<V> implements Future<V>, Serializable {}ForkJoinTask 是一个可以运行在 ForkJoinPool 线程池的任务的抽象基类,它实现了 Future 接口,意味着可以拿到任务执行的结果,而且这种类型的任务还可以扩展一些子任务;
也可以将一个 ForkJoinTask 实例看作一个线程实体,但是它要更加轻量。我们可以通过一个 ForkJoinPool 线程池,使用很少的线程就可以处理大量的任务及其衍生的子任务,仅仅需要付出一些使用限制。
小结
了解了 ForkJoinPool 以及 ForkJoinTask 后,再来简单分析一下:
ForkJoin框架是在 JDK 1.7 之后提出的,在并行处理大量任务时,可以提高处理效率;- 主要工作原理是将一个大任务分割成若干个小任务,最终汇总每个小任务的结果从而得到大任务结果的一个框架。
从名字上就可以看出来,Fork 就是把一个大任务切分为若干子任务并行执行;Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。
(Tip:其实这种方式是分治算法的并行版本。)
2、工作窃取算法
工作窃取算法(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。那么,为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,可以把这个任务分割为若干个互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列中去,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如 A 线程负责处理 A 队列里的任务。
但是,有的时候某些线程先把自己队列中的任务做完了,而其他线程对应的队列里还有任务等待处理,在这种情况下让已经完成工作的线程去等待明显是不合适的,于其等着,不如去帮其他线程干活,于是它就去其他线程的队列中窃取一个任务来执行。
此时,至少两个线程会去访问同一个队列,为了减少窃取任务线程和倍窃取任务线程之间的竞争,通常会使用 双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
采取工作窃取算法的 ForkJoinPool 工作流程如下:
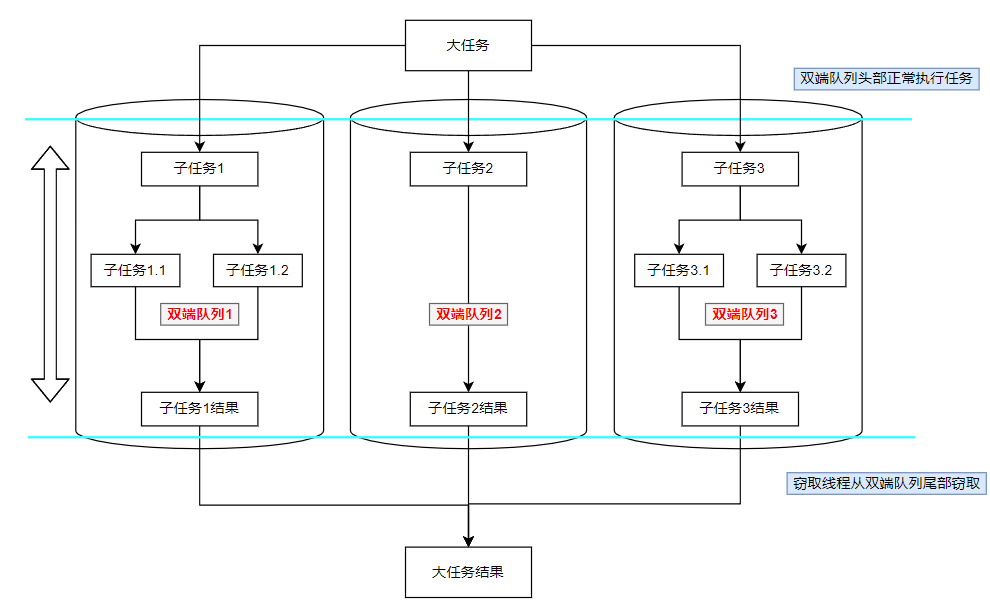
- 工作窃取算法的优点:充分利用线程来进行并行计算,减少了线程间的竞争;
- 工作窃取算法的缺点:在某些情况下还是存在资源竞争,比如双端队列里面只有一个任务时。并且该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。
3、Fork/Join 框架的设计
Fork/Join 框架的设计思路大概是这样的,对于一个大的任务:
(1)分割任务
首先我们需要一个 Fork 类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小;
(2)执行任务并合并结果
分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务并执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
Fork/Join 框架使用两个类来完成以上两件事情:
1、ForkJoinTask:ForkJoinPool 线程池处理的任务是 ForkJoin 任务。它提供在任务中执行 fork() 和 join() 操作的机制。通常情况下,我们不需要直接继承 ForkJoinTask 抽象类,只需要继承它的子类,Fork/Join 框架提供了以下几个直接子类:

其中我们用的多的有两个:
RecursiveAction:用于没有返回结果的任务;RecursiveTask:用于有返回结果的任务。
2、ForkJoinPoll:ForkJoinTask 需要通过ForkJoinPoll 来执行。
小结
任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
4、使用 Fork/Join 框架
要求:计算 1 + 2 + 3 + 4 的结果。
使用 Fork/Join 框架首先考虑到的是如何分割任务,如果希望每个子任务最多执行两个数的相加,那么我们设置分割的阈值是 2,由于是 4 个数相加,所以 Fork/Join 框架会把这个任务 fork 成两个子任务,最后 join 两个子任务的结果。因为是有结果的任务,所以必须继承 RecursiveTask。
代码如下:
public class CountTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 2; // 阈值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就直接计算,无需分割
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果大于阈值,就分割为两个子任务计算
int middle = (start + end) >>> 1;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完毕,并得到其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 生成一个计算任务,负责计算 1 + 2 + 3 + 4
CountTask task = new CountTask(1, 4);
// 提交一个任务
Future<Integer> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
}
}从例子中可以看到,ForkJoinTask 与一般任务的主要区别在于它需要实现 compute 方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务;任务不足够小,就必须分割成两个子任务,每个子任务在调用 fork 方法时,又会进入 compute 方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用 join 方法会等待子任务执行完并得到结果。
5、Fork/Join 框架的异常处理
ForkJoinTask 在执行的时候可能会抛出异常,但是我们没办法再主线程里直接捕获异常,所以 ForkJoinTask 提供了 isCompletedAbnormally() 方法来检查任务是否已经抛出异常或者已经被取消了,并且可以通过 ForkJoinTask 的 getException 方法获取异常。
使用如下代码:
if (task.isCompletedAbnormally()) {
System.out.println(task.getException());
}public final Throwable getException() {
int s = status & DONE_MASK;
return ((s >= NORMAL) ? null :
(s == CANCELLED) ? new CancellationException() :
getThrowableException());
}getException() 方法返回 Throwable 对象:
- 如果任务取消了则返回
CancellationException; - 如果任务没有完成或者没有抛出异常则返回 null。
二、补充:Java 8 并行流
1、顺序流和并行流
之前了解过 Java 8 的 Stream 接口,它可以让我们高效的处理集合元素,但 Stream 是顺序流,如果想将集合转换为并行流,则需要使用 parallelStream 方法。
并行流就是把一个内容分成多个数据块,并调用不同的线程分别处理每个数据块的流,这样就可以充分利用多核的优势。
我们现在可以重构上面使用 Fork/Join 框架求和案例:
(1)先看顺序流的做法:
Long reduce = Stream.iterate(1L, i -> i + 1)
.limit(1_000_000_000L)
.reduce(0L, Long::sum);等价于:
long sum = 0;
for (long i = 1L; i <= 1_000_000_000L; i++) {
sum += i;
}(2)并行流
可以通过 parallel 方法将顺序流转换为并行流:
Long reduce = Stream.iterate(1L, i -> i + 1)
.limit(1_000_000_000L)
.parallel()
.reduce(0L, Long::sum);转换为并行流后,Stream 在内部分成了几块,对不同的块独立进行归纳操作,最终得到整个原始流的归纳结果。
需要注意的是,对顺序流调用 parallel 方法并不意味着流本身有任何变化,它在内部实际上就是设置了一个标志,表示你想让调用 parallel 之后进行的所有操作都并行执行。类似的,可以对并行流调用 sequential 方法就可以把它变成顺序流,这两个方法如果同时使用,流的性质取绝于最后使用的方法。
2、并行流的实质
并行流内部使用了默认的 ForkJoinPool,默认的线程数量就是实际机器的处理器数量,通过 Runtime.getRuntime().availableProcessors() 得到,但是我们也可以通过系统属性 java.util.concurrent.ForkJoinPool.common.parallelism 来改变线程池大小,代码如下:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12")这是一个全局设置,它会影响所有的并行流,不过一般不会改这个属性。
3、装箱和拆箱
上面的代码中我们使用了 Stream.iterate 方法来构建自然数序列,这里有两个问题:
(1)iterate 方法生成的是装箱的对象,而在求和的时候必须拆箱成数字才可以求和;
(2)将 iterate 分成多个独立块来并行执行其实是有难度的;
4、原始类型流
既然使用 iterate 方法生成自然数序列存在一些问题,那么有没有更好的方法使流更高效的求和呢?
对于其他原始类型 double、float、long、short、short、char、byte 以及 boolean ,Stream API 提供了 IntStream、LongStream 以及 DoubleStream 等类型,专门用来直接存储原始类型值,不必使用包装。
- 使用
IntStream存储short、char、byte; - 使用
DoubleStream存储float; - 注意:Stream API 的设计者认为不需要为剩下的 5 种原始类型都添加对应的专门类型。
可以使用 LongStream.rangeClosed 方法生成 long 类型的流,该方法和 iterate 相比有两个优点:
LongStream.rangeClosed直接产生原始类型的 long 数字,没有装箱拆箱的消耗;LongStream.rangeClosed(long startInclusive, final long endInclusive)生成数字的范围是[start, end],因此很容易就拆分为独立的小块。
// 顺序流计算原始类型
LongStream.rangeClosed(1L, 1_000_000_000L).reduce(0L, Long::sum);
// 并行流计算原始类型,比前者快了大概 3 倍
LongStream.rangeClosed(1L, 1_000_000_000L).parallel().reduce(0L, Long::sum);


