锁的内存语义
总所周知,锁可以让临界区互斥执行。这里介绍锁的另一个重要的功能:锁的内存语义。
1、锁的释放-获取建立的 happens-before 关系
锁是 Java 并发编程中最重要的同步机制。锁除了让临界区互斥执行以外,还可以让释放锁的线程向获取同一个锁的线程发送消息。
例如:
public class MonitorExample {
int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
// ...
} // 6
}假设线程 A 执行 writer() 方法,随后线程 B 执行 reader() 方法。根据 happens-before 规则,这个过程中包含的 happens-before 关系可以分为三类:
(1)根据程序次序规则:1 happens-before 2,2 happens-before 3,4 happens-before 5,5 happens-before 6
(2)根据监视器锁规则:3 happens-before 4
(3)根据 happens-before 的传递性:2 happens-before 5
图形化表现如下:
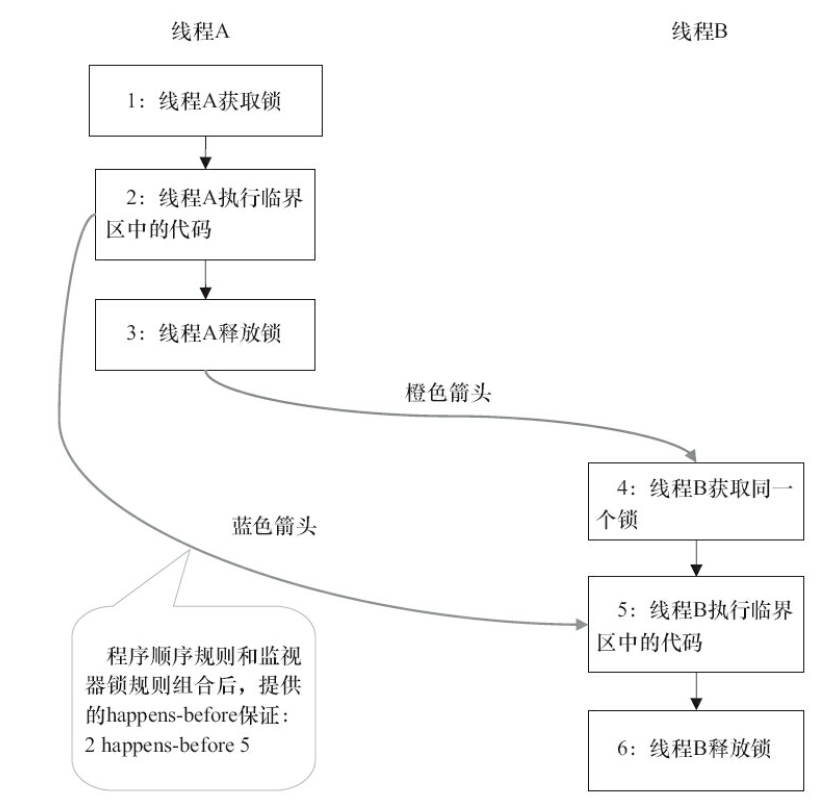
线程 A 释放了锁之后,随后线程 B 获得了同一个锁。2 happens-before 5,因此,线程 A 在释放锁之前所有可见的共享变量,在线程 B 获取同一个锁之后,将立刻变得对线程 B 可见。
2、锁的释放和获取的内存语义
当线程释放锁后,JMM 会把该线程对应的本地内存中的共享变量刷新到主内存中。以上面的 MonitorExample 程序为例,A 线程释放锁后,共享数据的状态示意图:

当线程获取锁时,JMM 会把该线程对应的本地内存置为无效。从而使得被监视器保护的临界区代码必须从主内存中读取共享变量。

对比锁释放-获取的内存语义与 volatile 写-读的内存语义可以看出:锁释放与 volatile 写有相同的内存语义;锁获取与 volatile 读有相同的内存语义。
总结
- 线程 A 释放一个锁,实质上是线程 A 向接下来要获取这个锁的某个线程发出了(线程 A 对共享变量所作修改的)消息。
- 线程 B 获取一个锁,实质上是线程 B 接收了之前某个线程发出的(在释放这个锁之前对共享变量所做修改的)消息。
- 线程 A 释放锁,随后线程 B 获取这个锁,这个过程实质上是线程 A 通过主内存向线程 B 发送消息。
3、锁内存语义的实现
(1)ReentrantLock
看一下使用 ReentrantLock 的例子:
class ReentrantLockExample {
int a = 0;
ReentrantLock lock = new ReentrantLock();
public void writer() { // 获取锁
lock.lock();
try {
a ++;
} finally {
lock.unlock(); // 释放锁
}
}
public void reader() { // 获取锁
lock.lock();
try {
int i = a;
// ...
} finally {
lock.unlock(); // 释放锁
}
}
}在 ReentrantLock 中,调用 lock() 方法获取锁;调用 unlock() 方法释放锁。
ReentrantLock 的实现依赖于 Java 同步器框架 AbstractQueuedSynchronizer(AQS,抽象同步队列)。
AQS 使用一个整型的 volatile 变量(命名为 state)来维护同步状态,这个 volatile 变量是 ReentrantLock 内存语义实现的关键。
下图为 ReentrantLock 的部分类图:

(2)公平锁和非公平锁
ReentrantLock 分为公平锁和非公平锁,首先分析公平锁:
使用公平锁时,加锁方法 lock() 的调用轨迹如下:
(1)ReentrantLock#lock()
(2)FairSync#lock()
(3)AbstractQueuedSynchronizer#acquire(int arg)
(4)FairSync#tryAcquire(int acquires)
到第四步真正开始加锁,该方法源码:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState(); // 获取锁的开始, 首先读 volatile 变量 state
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}加锁方法首先读 volatile 变量 state。
在使用公平锁时,解锁方法 unlock() 的调用轨迹如下:
(1)ReentrantLock#unlock()
(2)AbstractQueuedSynchronizer#release(int arg)
(3)Sync#tryRelease(int releases)
在第三步真正开始释放锁,下面是该方法的源码:
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c); // 释放锁的最后,写 volatile 变量 state
return free;
}从源码可以看出,在释放锁的最后写 volatile 变量 state。
公平锁在释放锁的最后写 volatile 变量 state,在获取锁时首先读这个 volatile 变量。根据 volatile 的 happens-before 规则,释放锁的线程在写 volatile 变量之前可见的共享变量,在获取锁的线程读取同一个 volatile 变量后将立即变得对获取锁的线程可见。
现在分析一下非公平锁的内存语义的实现。非公平锁的释放和公平锁完全一样,所以这里仅仅分析非公平锁的获取。使用非公平锁时,加锁方法 lock() 的调用轨迹如下:
(1)ReentrantLock#lock()
(2)NonfairSync#lock()
(3)AbstractQueuedSynchronizer#acquire(int arg)
(4)NonfairSync#tryAcquire(int acquires)
(5)Sync#nonfairTryAcquire(int acquires)
到第五步才开始真正加锁:
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}这里用到了 compareAndSetState 方法(简称 CAS),该方法以原子操作的方式更新 state 变量。
JDK 文档对该方法说明如下:如果当前状态值等于预期值,则以原子方式将同步状态设置为给定的更新值。此操作具有 volatile 读和写的内存语义。
(3)CAS 的实现
这里我们从编译器和处理器的角度来分析,CAS 如何同时具有 volatile 读和 volatile 写的内存语义。
之前提到过,编译器不会对 volatile 读与 volatile 读后面的任意内存操作作重排序;编译器不会对 volatile 写与 volatile 写前面的任意内存操作作重排序。组合这两个条件,意味着为了同时实现 volatile 读和 volatile 写的内存语义,编译器不能对 CAS 与 CAS 前面和后面的任意内存操作作重排序。
下面分析在常见的 intel X86 处理器中,CAS 是如何同时具有 volatile 读和 volatile 写的内存语义的。
下面是 sum.misc.Unsafe 类的 compareAndSwapInt() 方法的源代码:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
// 换个参数说明
public final native boolean compareAndSwapInt(Object o, long offest, int expect, int update);可以看到,这是一个本地方法调用。这个本地方法的最终实现在 openjdk 中源代码为:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}程序会根据当前处理器的类型来决定是否为 cmpxchg 指令添加 lock 前缀。如果程序是在多处理器上运行的,就为 cmpxchg 指令加上 lock 前缀(Lock Cmpxchg)。反之,如果程序是在单处理器上运行的,就省略 lock 前缀(单处理器自身会维护单处理器内的顺序一致性,不需要 lock 前缀提供的内存屏障效果)。
intel 的手册对 lock 前缀说明如下:
(1)确保对内存的 读-改-写 操作原子执行。在 Pentium 及 Pentium 之前的处理器中,带有 lock 前缀的指令会在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。很显然,这会带来昂贵的开销。从 Pentium4、Intel Xeon 及 P6 处理器开始,Intel 使用缓存锁定(Cache Locking)来保证指令执行的原子性。缓存锁定将大大降低 lock 前缀指令的执行开销。
(2)禁止改指令与之前和之后的读和写指令重排序。
(3)把写缓冲区中的所有数据刷新到内存中。
上面的 2、3 两点所具有的内存屏障效果,足以同时实现 volatile 读和 volatile 写的内存语义。
经过上的分析,我们终于明白了为什么 JDK 文档说 CAS 同时具有 volatile 读和 volatile 写的内存语义了。
(4)总结
现在对公平锁和非公平锁的内存语义做个总结:
- 公平锁和非公平锁释放时,最后都要写一个 volatile 变量的 state;
- 公平锁和非公平锁获取时,首先会去读 volatile 变量,然后用 CAS 更新 volatile 变量,这个操作同时具有 volatile 读和 volatile 写的内存语义。
从前面对 ReentrantLock 的分析,可知锁释放-获取的内存语义的实现至少有下面两种方式:
(1)利用 volatile 变量的写-读所具有的内存语义;
(2)利用 CAS 所附带的 volatile 读和 volatile 写的内存语义。
4、concurrent 包的实现
由于 Java 的 CAS 同时具有 volatile 读和 volatile 写的内存语义,因此 Java 线程之间的通信现在有了四种方式:
(1)A 线程写 volatile 变量,随后 B 线程读这个 volatile 变量;
(2)A 线程写 volatile 变量,随后 B 线程用 CAS 更新这个 volatile 变量;
(3)A 线程用 CAS 更新一个 volatile 变量,随后 B 线程用 CAS 更新这个 volatile 变量;
(4)A 线程用 CAS 更新一个 volatile 变量,随后 B 线程读这个 volatile 变量。
Java 的 CAS 会使用现代处理器上提供的高效机器级别的原子指令,这些原子指令以原子方式对内存执行 读-改-写 操作,这是在多处理器中实现同步的关键(从本质上来说,能够支持原子性读-改-写指令的计算机,是顺序计算图灵机的异步等价机器,因此任何现代的多处理器都会去支持某种能对内存执行原子性读-改-写操作的原子指令)。同时 volatile 变量的 读/写 和 CAS 可以实现线程之间的通信。
把这些特性整合起来,就形成了整个 concurrent 包得以实现的基石。
如果我们仔细分析 concurrent 包的源代码实现,会发现一个通用化的实现模式。
(1)首先,声明共享变量为 volatile;
(2)然后,使用 CAS 的原子条件更新来实现线程之间的同步;
(3)同时,配合以 volatile 的读/写和 CAS 所具有的 volatile 读和写的内存语义来实现线程之间的通信。
AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些 concurrent 包中的基础类都是使用这种模式来实现的,而 concurrent 包中的高层类又是依赖这些基础类来实现的。
从整体上看,concurrent 包的实现示意图如下所示:




